
今回Embulkを初めて触ってみたので内容を残しておきます
やったこと

- ローカルPCにEmbulkをインストール
- dockerでMySQL立ち上げ&ダミーDB(sakila)を作成
- EmbulkでMySQLからデータ取得
- EmbulkでS3にアップロード
ローカルPCにEmbulkをインストール
公式サイトに載っているコマンドをそのまま実行すると特に詰まることもなくインストールが完了しました
$curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
$chmod +x ~/.embulk/bin/embulk
$echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
$source ~/.bashrc
$embulk --version
> embulk 0.9.24embulkのjarファイルをダウンロードして、実行権限を付与して、パスを通すだけです
dockerでMySQL立ち上げ&ダミーDB(sakila)を作成
今回はこちらのdockerを使わせていただいて、実際に100秒以内でMySQL環境を準備することができました(しかもサンプルDBも作成済み)
EmbulkでMySQLからデータ取得
登場する主なembulkコマンドを先に載せておきます
| embulk bundle install … | Gemfileに記載されているプラグインをinstall |
| embulk guess … | seedからconfigを生成 |
| embulk preview … | configの内容をdryrun |
| embulk run … | configの内容を実行 |
bundleプラグインでGemfileを生成
プラグインを管理するためのbundleと呼ばれるツールを作成します
$embulk mkbundle bundle
$cd bundle/bundle
├── Gemfile
└── embulk
├── filter
│ └── example.rb
├── input
│ └── example.rb
└── output
└── example.rbGemfile(PythonのRequirements.txtのような役割)が生成できるのでここに必要なプラグインを記述する流れになります
embulk-input-mysqlをインストール
Gemfileにインストールしたいプラグイン名を設定します
...
# Specify the exact prerelease version (like '= 0.9.0.beta') for prereleases.
gem 'embulk'
gem 'embulk-input-mysql' <-- ここを追記
...インストール実行
$embulk bundle install --path=vendor/bundleembulk bundle listコマンドで確認
takashis-Air:bundle otakashi$ embulk bundle list
2022-09-01 18:13:22.222 +0900: Embulk v0.9.24
Gems included by the bundle:
* bundler (1.16.0)
* embulk (0.10.36)
* embulk-input-mysql (0.13.0)
* msgpack (1.4.1)embulk-input-mysqlが表示されているので正常にインストールされていることが確認できました
MySQLに接続
mysql-s3フォルダの配下にseed.ymlを配置します
mysql-s3
└── seed.ymlseed.ymlは下記の内容で作成(今回はDBの接続情報はベタ書き)
in:
type: mysql
host: 127.0.0.1
user: root
password: "root"
database: sakila
query: |
SELECT
address_id
FROM
address
;
out:
type: stdoutembulk guessを実行しconfig.ymlを生成
embulk guess ./seed.yml -o config.yml -b ../bundleでconfig.ymlの生成を試みましたが、エラーが発生
PCにinstallしているembulkのバージョンとGemfileで指定しているembulkのバージョンが違っているようです
Running Embulk version (0.9.24) does not match the installed embulk.gem version (0.10.36).Gemfileのembulkのversionを修正し、もう一度embulk bundle を実行することで修正で解消できました
...
gem 'embulk', '= 0.9.24' <-- ここをバージョン指定
gem 'embulk-input-mysql'再度embulk guess ./seed.yml -o config.yml -b ../bundle を実行しconfig.ymlが生成されました
in:
type: mysql
host: 127.0.0.1
user: root
password: root
database: sakila
query: |
SELECT
address_id
FROM
address
;
out: {type: stdout}outの部分しか変わっていないですね(チュートリアルではinput対象がcsvだったため各カラムの型情報が出力されていたのですが、今回はそういうのはないのね…)
プレビュー実行
embulk preview -b ../bundle config.ymlを実行すると結果が標準出力されました
2022-09-01 18:52:24.030 +0900 [INFO] (0001:preview): Fetched 500 rows.
+-----------------+
| address_id:long |
+-----------------+
| 56 |
| 105 |
| 457 |
| 491 |
| 332 |
....EmbulkでS3にアップロード
備考: ローカルPCにてAWSのcredentialsの設定をしている状態(AWS cli でアクセスできる状態)になっています
embulk-output-s3_parquetをインストール
Gemfileにgem 'embulk-output-s3_parquet'を追記してembulk bundle install --path=vendor/bundleを実行
seed.ymlを用意
先ほどのSELECT文に取得するカラムを増やしました
path/prefixの項目で出力するフォルダ階層とファイルのprefixの設定が可能なようです
in:
type: mysql
host: 127.0.0.1
user: root
password: root
database: sakila
query: |
SELECT
address_id,
address,
address2,
district,
city_id,
postal_code,
phone,
last_update
FROM
address
;
out:
type: s3_parquet
region: ap-northeast-1
bucket: embulk-parquet
path_prefix: address/address_
file_ext: snappy.parquet
compression_codec: snappy
default_timezone: Asia/Tokyoconfig.ymlを更新
embulk guess ./seed.yml -o config.yml -b ../bundleseed.ymlに記載した内容とほぼ変わりなく、outの箇所がjsonになっただけでした
...
out: {type: s3_parquet, region: ap-northeast-1, bucket: embulk-parquet, path_prefix: address/address_,
file_ext: snappy.parquet, compression_codec: snappy, default_timezone: Asia/Tokyo}embulk run実行
embulk run -b ../bundle config.yml約7秒で500件のデータ転送が完了(なんかあっさり終わった感)
データの確認
S3にparquetでアップロードされていることを確認
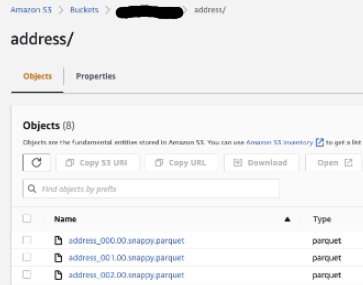
Crawlerを回すとAthenaからも参照できます
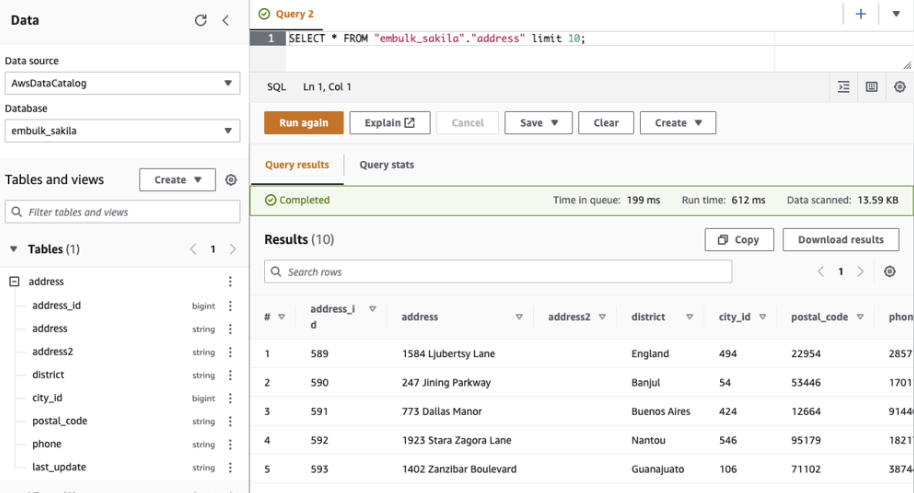
last_updateカラムがstringと認識されているため、この部分については値のフォーマットをembulk側で対応する必要がありそうです
感想
- 学習コストがある程度かかる印象だったけど、複雑なことをしなければシンプルでいけそう
- プラグインを使ってなんぼのツールなので、そういう意味ではプラグインごとの使い方を学ぶ必要があり学習コストが嵩むかも
- もうちょっと調べたいこととしては、「DBからテーブルの型情報を取得できるか(Glue Crawlerの役割を担えるか)」、「処理速度」、「digdagとどう使うのか」

