Databricks on AWSを触り始めたので、学んだことを残しておきます
特にAWS上でデータ基盤を構築してきた人がDatabricksにとっつきやすくなるような記事を書くことを心がけます
背景
AWS のGlue やAthena中心に実装・運用していたので、最初はDatabricksのサービス名や用語の意味を捉えきれず、なかなかDatabricksの全貌が見えきませんでした
徐々にわかってきたことが溜まってきたので、下記に羅列しました
用語集
Unity Catalog
databricksのデータカタログ機能の名称
AWS Glue DataCatalog全体をイメージすると良いかも
Managed table(マネージドテーブル)
Databricks でUnity Catalogに作成したDelta Lake Formatを読み込むためのテーブル
External table(外部テーブル)
Databricks以外のクラウドサービスに存在するテーブル
外部からDatabricksで管理しているデータを読み込むためのテーブル
参考: AthenaからDeltatableのデータをReadする その2
DatabricksからCREATE EXTERNAL TABLE を実行するとGlue のDataCatalogにテーブルが追加される
Delta Lake (Format)
databricksで扱うデータの形式の名称
例) S3にあるparquetファイルをDelta Lakeに変換した場合
ファイルの形式はparquetのままだが、databricksで扱うためのメタデータも出力される
変換方法の一つはS3のデータをソースとしてUnity Catalogでテーブルを作成する
※他の方法はまだ触ったことないです
Delta Live Tables
サービスの名称
参考: 「データとAIの民主化」をさらに加速させる4つの革新的な新機能を発表
アナリティクスや機械学習に使用する際に、データがクリーンで一貫性のあるものになるように、Delta Lake上でETL(抽出、変換、ロード機能)を簡単かつ信頼性の高いものにするクラウドサービスです。信頼性の高いデータパイプラインでレイクハウスの基盤を構築します。
まだ触ってないので詳しくは不明です
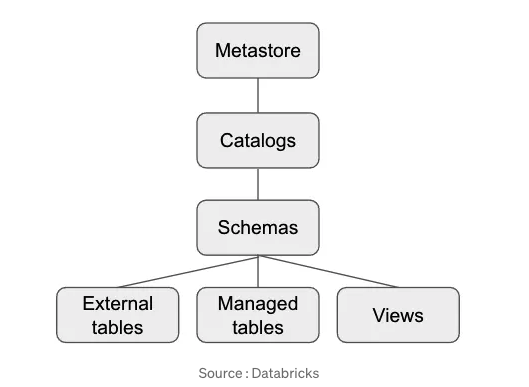
Metastore(Unity Catalog metastore)
下図で表現されている通り、Catalog, Schema, tables, viewsを管理するもの
compute (cluster)
computeとclusterはほぼ同じ意味で使われている印象
databricks on AWS の場合、EC2 instanceをdatabricksが使用する
私が動かしたサービスでは用途によって3種類のcomputeが使い分けられていた
- SQL warehouse
SQLウェアハウスはDatabricks SQLのデータオブジェクトに対してSQLコマンドを実行する計算リソース
SQL Editorでデータを抽出時に起動していた
AWS でAthenaを実行した時をイメージしてください - All-purpose compute
Notebookの実行時(sparkでデータ抽出&テーブルに出力)に起動していた
AWSでイメージすると
CFnでGlue Datacatalogのテーブルを作成して、Glue JobでS3からデータを取得、変換、S3に出力する一連の処理をイメージしてください - (job compute)
dbtを使ってdelta lakeのデータを変換して、S3に出力した際起動していたcompute
今回の場合はdbt CLIという名称のdefalutで存在していたdbt cliを実行するためのcomputeを使用
`All-purpose computeのcomputeを選択してjobを動かすことも可能(job作成時に選択できる)
結論
これからいくつかDatabricksの記事を書く予定です
Databricksを触っていく過程で新たな発見があればこの記事に反映していきます!
