
やったこと
- AWS DMSを利用してOracleからAuroraPGへFull load+CDC(Migrate and replicate)を実施
- エラーは発生しないが一部のテーブルでCDCが正しく動いていないことが発覚
- CDCが動いていないテーブルにカラム名が30bytesを超えるカラムが存在することが原因だった
- DMSのログ読み取り方式をLogMinerからBinaryReaderに変更することで正しくCDCが動いた
問題
カラム名が30bytesを超えるカラムが存在すると、Full loadは動くがCDCは動かなかった…
具体的にはDMS TaskのStatusはLoad complete, replication ongoing になっているものの、
Source側にデータ更新を行なっても何もTargetに反映されない状態です
ちゃんとドキュメントに書かれているので仕方ない問題ですね
AWS DMS doesn’t support long object names (over 30 bytes).
対応策
設定
Endpoint設定にExtra connection attributesの項目があるのでそこにuseLogMinerReader=N;useBfile=Y を設定する
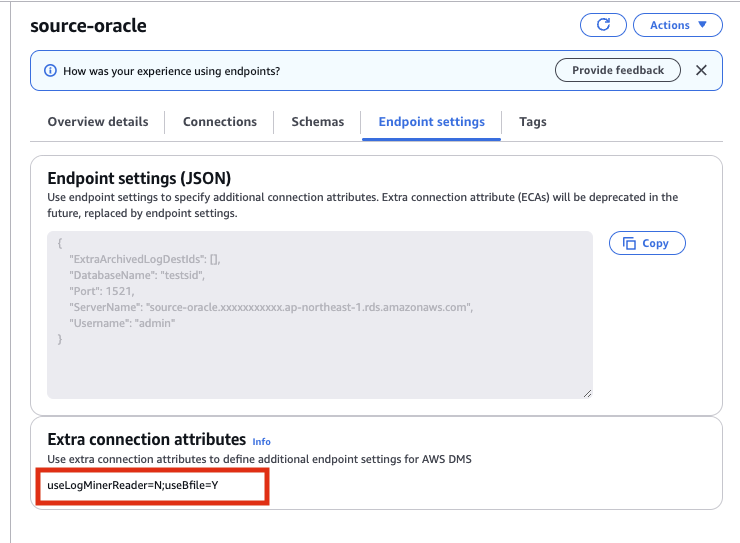
私の場合 AWS DMSのドキュメント に書かれている設定をそのまま設定して結果的に動いたけど、Oracleの環境設定によって他に設定が必要になるケースはありそう
Endpointの設定以外は通常通りDMS Taskを作成して、このEndpointに紐付ける
DMS Taskのmapping rulesは下記の通り
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "SAMPLE",
"table-name": "EXCEED_30_BYTES"
},
"rule-action": "include"
},
{
"rule-type": "selection",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "SAMPLE",
"table-name": "NOT_EXCEED_30_BYTES"
},
"rule-action": "include"
},
{
"rule-type": "transformation",
"rule-id": "3",
"rule-name": "3",
"rule-target": "column",
"object-locator": {
"schema-name": "%",
"table-name": "%",
"column-name": "%"
},
"rule-action": "convert-lowercase",
"value": null,
"old-value": null
},
{
"rule-type": "transformation",
"rule-id": "4",
"rule-name": "4",
"rule-target": "table",
"object-locator": {
"schema-name": "%",
"table-name": "%"
},
"rule-action": "convert-lowercase",
"value": null,
"old-value": null
},
{
"rule-type": "transformation",
"rule-id": "5",
"rule-name": "5",
"rule-target": "schema",
"object-locator": {
"schema-name": "%"
},
"rule-action": "convert-lowercase",
"value": null,
"old-value": null
}
]
}動作確認
TaskをRestartし、full loadが完了後 source側のテーブルにレコードを登録すると、Target側のAuroraPGに反映されていることが確認できた
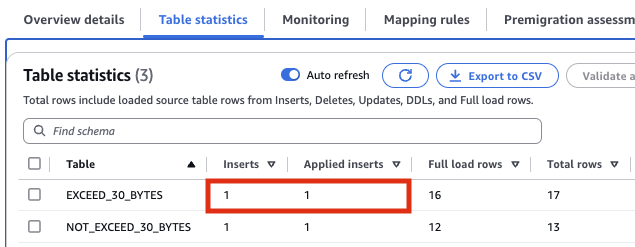
(EXCEED_30_BYTES がカラム名30bytes超えのカラムを持つテーブル)
試したけどダメだった
LogMiner設定の状態でDMS Taskのmapping rulesをいじってみましたが無駄でした
1. カラム名のrename
30bytesを超えるカラム名を短いカラム名に変換
–> CDCは稼働しなかった
2. カラム名の変更設定(make lowercase)を全て除去
–> CDCは稼働しなかった
3. 特定カラム除去(remove-column)
–> Full load時にカラムはremoveされず、さらにCDCは稼働しない状態
まとめ
試してはないですが、Table名が30bytesを超える場合でもBinary Readerであれば問題なく動くはず
Binary Readerでやるための設定は簡単ですが、組織ごとにいろいろ制約があるはずなので問題はそこですよね…
