
はじめに
ややこしいタイトルつけちゃった…
SQLのWindow関数の使い方を忘れてしまうのでここに残しておきます
なお、サンプルはPostgresを使用しました
「同じkey(カラムの値)をレコードのうち、特定のカラムの値を順序が高いのものみ取り出す、をテーブルに存在する同じkey(カラムの値)の数分だけ繰り返す」をゴールとした記事です
(AWSで例えると)S3にcsv, parquetなでのデータファイルを(削除、更新を行わず)アップロードのみ行うフローをDatalakeなどに採用していると、
Athenaからデータ参照する時、「PrimaryKeyごとに最新のレコードのみ抽出する」ケースが発生すると思います
window関数を使う
サンプルを作成するために使ったSQLは記事の末尾に載せておきます
ひとまず順序を加える
同じkey(今回はuser_id, group_code)の中で、ある値(今回はsystem_updated_at, datalake_updated_at)を並べ変えて追加カラム(_rank)に順序を数値としてふる
SELECT *, ROW_NUMBER() OVER(
PARTITION BY user_id, group_code
ORDER BY system_updated_at DESC, datalake_updated_at DESC) AS _rank
FROM public.window_samples;結果
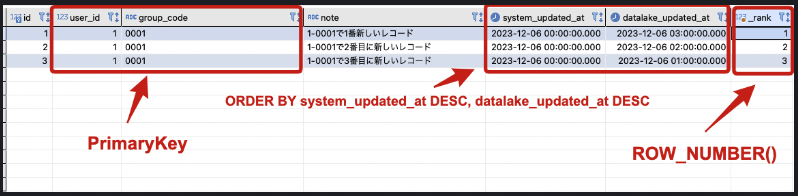
さらにサブクエリで_rankが1のものだけ取り出す
データを増やす
先ほどと同類のデータを「user_id:2, group_code:0002」と「user_id:3, group_code:0003」として追加しました
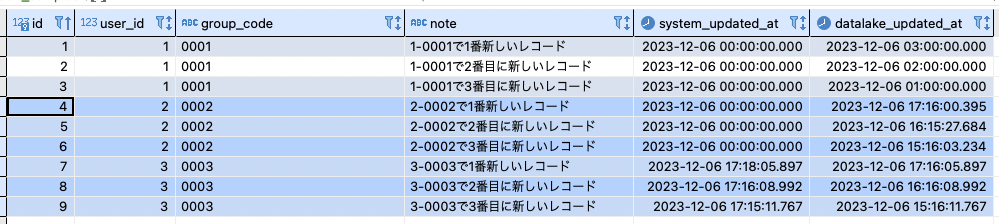
そこで先程のwindow関数を使ったSELECT文をサブクエリとして、_rankが1のもののみ取り出す という条件を追加しました
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER(
PARTITION BY user_id, group_code
ORDER BY system_updated_at DESC, datalake_updated_at DESC) AS _rank
FROM public.window_samples
) as samaple
WHERE _rank = 1;結果
「user_id,group_code」それぞれのまとまりの内、timestampが最新のものを抽出することができました
具体的には
「user_id:1, group_code:0001のレコードのうち、system_updated_atとdatalake_updated_atが最新のレコード」
「user_id:2, group_code:0002のレコードのうち、system_updated_atとdatalake_updated_atが最新のレコード」
「user_id:3, group_code:0003のレコードのうち、system_updated_atとdatalake_updated_atが最新のレコード」
を抽出した状態です

使用したSQL
CREATE TABLE public.window_samples (
id int4 NOT NULL,
user_id int4 NOT NULL,
group_code bpchar(100) NOT NULL,
note bpchar(100),
system_updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
datalake_updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT window_samples_pkey PRIMARY KEY (id)
);
-- 記事中ではsystem_updated_at, datalake_updated_atをいい感じにイジってます
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(1, 1, '0001', '1-0001で1番新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(2, 1, '0001', '1-0001で2番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '1 hours');
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(3, 1, '0001', '1-0001で3番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '2 hours');
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(4, 2, '0002', '2-0002で1番新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(5, 2, '0002', '2-0002で2番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '1 hours');
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(6, 2, '0002', '2-0002で3番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '2 hours');
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(7, 3, '0003', '3-0003で1番新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(8, 3, '0003', '3-0003で2番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '1 hours');
INSERT INTO public.window_samples
(id, user_id, group_code, note, system_updated_at, datalake_updated_at)
VALUES(9, 3, '0003', '3-0003で3番目に新しいレコード', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP - interval '2 hours');
まとめ
データ基盤に関わるまでwindow関数を使ったことがなかったです
使う頻度は少なくても、これくらいはパッと書けるようになりたいと思い記事にしました
今試しに書いてみます
select *, row_number() over(
partition by col_a, col_b
order by timestamp_a desc
) as col_name
案外いけた…
