
Schemaの更新
データにはエントロピー(乱雑さ度合い)があり、あなたの管理や同意なしに変更される可能性がある
– データソースのスキーマ変更
– 新しいフィールドの追加
列ベースのシステムの利点
– データの更新はより困難だけど、スキーマの更新が簡単
このような技術的な改善にもかかわらず、実際的な組織のスキーマ管理はより困難
– スキーマ更新の自動化(Fivetranがソースからレプリケートする際に使用しているアプローチ)は
– 便利そうに聞こえますが、下流の変換が壊れるリスクもある
– 簡単なスキーマ更新リクエストプロセスはありますか?
– レビュープロセス
– ダウンストリームプロセスへの影響チェック
– 作業時間の見積もり
最近の半構造化データ(JSONなど)の扱いが便利になった
多くのクラウドデータウェアハウスは、ドキュメントストアのアイデアを借りて、任意のJSONデータをエンコードするデータ型をサポートしている
– 生のJSONをフィールドに格納し、頻繁にアクセスされるデータを隣接する平坦化されたフィールドに格納する
– JSONフィールドに頻繁にアクセスされるデータは、時間の経過とともにスキーマに直接追加することができる
– これにより、半構造化データは非常に柔軟で、データが行や列に制約されなくなる
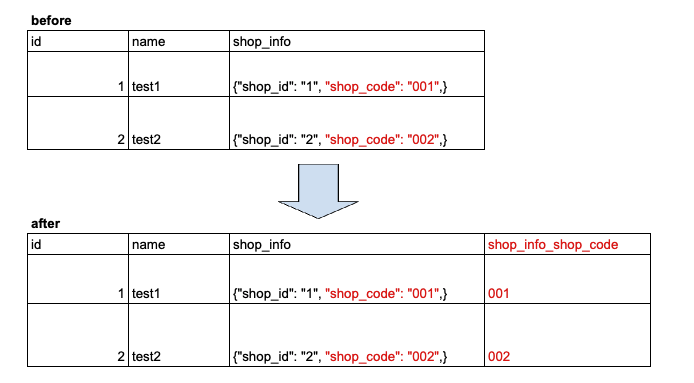
自動でこれをやってくれるとすごく便利 自動でやってくれる訳ではないのか….
データラングリング
データ・ラングリングは、乱雑で不正なデータを、有用でクリーンなデータに変換する
– 一般的にバッチ変換プロセス
– Dataを wrangling(飼い慣らす)
データラングリングのこれまで
EDIデータを受け取り、大まかな形にするまでに作業量が多い
※Electronic Data Interchange: 契約書・発注書・受注書・納品書・請求書など
– ひとまず行全体を単一のフィールドへ取り込む
– データを解析・分解するクエリーを書く
– 時間をかけて異常・エッジケースを発見
– ここで初めて下流の変換プロセスを開始できる
データラングリングツールとは
このプロセスを簡素化してくれる
データエンジニアはNo Codeツールを敬遠しがち
でも著者はデータ・ラングリングツールを、不正なデータのための統合開発環境(IDE)と考えたい
これらの自動化ツールのおかげで作業工数を節約できる
データラングリングツールが助けてくれること
- データサンプルをビジュアライズなインターフェースで表示
- 推論されたタイプ、分布、異常データ、外れ値、null値などの統計情報を表示してくれる
- ユーザは(ワークフローに?)ステップを追加できる
- ミスタイプされたデータの処理
- テキストフィールドの分割
- 大規模データの場合Sparkのようなスケーラブルなデータ処理システムにpushされて処理する
データラングリングツールはおすすめ
主要なクラウドプラバイダーはデータラングリングツールを提供している
仕事の特定部分を大幅に効率化してくれる
組織的には、データエンジニアリングチームは、新しくて乱雑なデータソースからのインジェストを頻繁に行う場合、データラングリングのスペシャリストのトレーニングを検討するとよい
AWS Data Wrangler – What’s it, and How to use it? (beginner friendly)
特徴を列挙
- No Code
- データソースはS3, Redshiftなどいろいろ
- 300種類以上の変換パターンを用意
- one host encodingなど(参考: ダミー変数(One-Hotエンコーディング)とは?実装コードを交えて徹底解説)
- 正規化
- imputation of missing data: 欠測データの補完
- 可視化もサポート(bar charts, line plots, histograms, scatterplots)
Sparkのdata変換例
Spark, Airflow, S3を使った一連の処理フロー
- Airflowは、3つの異なるAPIソースからのデータをJSON形式で取得
- 取得されたデータは、それぞれのソースに対応するプレフィックス(ファイルパス)を持つS3バケットに保存
- Airflowは、SparkジョブをトリガーするためにAPIを呼び出す
- Sparkジョブは、各ソースからのデータを取り込み、それぞれのデータをデータフレームに変換
- データフレーム内の特定の列にはネストされた構造があり、それをリレーショナル形式に変換
- 各ソースからのデータを1つのテーブルに結合
- SQLステートメントを使用して、結果を必要な情報にフィルタリング
- フィルタリングされた結果はParquet形式のDelta Lakeテーブルに書き込まれ、S3に保存される
- Sparkは、データ取り込み、結合、および書き込みのためのコードに基づいてステップのDAGを作成する
> Each data source gets its prefix (filepath) in an S3 bucket.
これは「S3に保存する」という理解であっているのか…
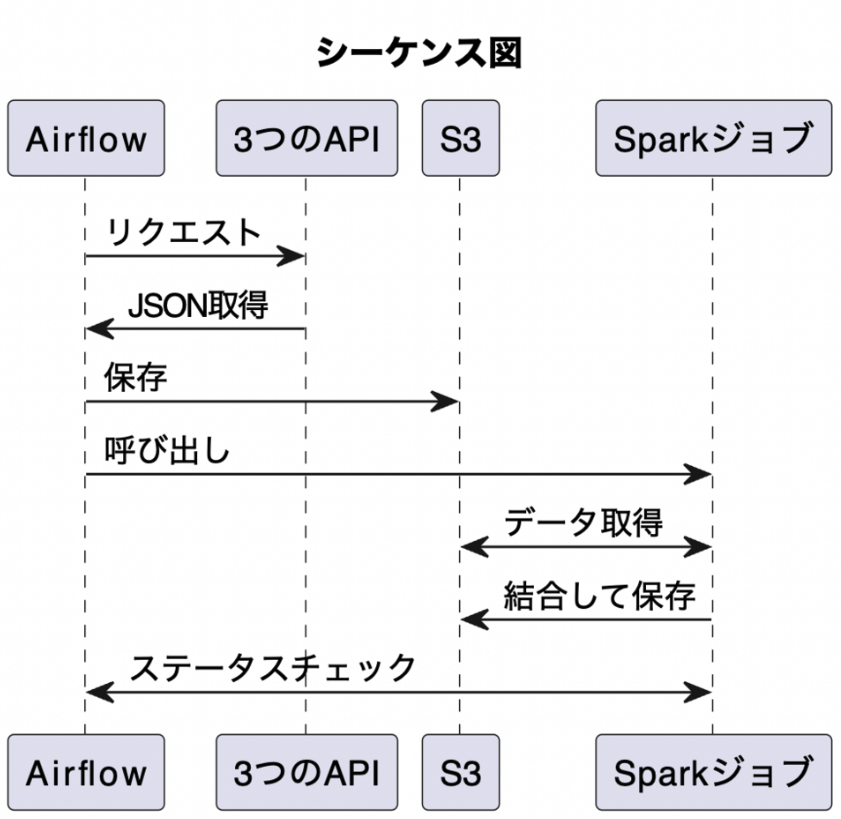
DAG(ワークフロー)は2つ
Airflow
APIからjsonを取得
S3へ保存
Sparkジョブを呼び出し
Sparkジョブのステータスをポーリング
Sparkジョブが完了すると処理終了 Sparkジョブ
データ読み込み(補足1)
データフレームに変換
ネストされた構造をリレーショナル形式に変換
各ソースを1つのテーブルに結合(補足2)、フィルタリング
S3にDelta Lakeフォーマットで書き込み- データ読み込み(補足1)
データの基本的な取り込みはクラスタメモリ内で行われますが、データの1つは大きすぎて取り込み中にクラスタメモリに収まりきらない場合があります。そのような場合、データは一時的にディスクに書き出されますが、これはクラスタのストレージに書き込まれます - 各ソースを1つのテーブルに結合(補足2)
データが異なるクラスタノードに分散されているため、効果的な結合を行うためには、データの再分配(シャッフル)が必要
しかし、データを再分配する際、データがクラスタのメモリに収まりきらない場合、一部のデータはディスクに書き出される、これがスパイル
ビジネスロジックと派生データについての話
問題定義
変換の最も一般的な使用例の1つは、ビジネスロジックをレンダリング(演算)すること
バッチ変換、ストリーミング変換どちらでも発生する可能性がある
例)
ある企業が、複数の特殊な内部利益計算を使用している
いろいろな計算結果が必要
– マーケティングコスト差し引き前の利益
– マーケティングコストを差し引いた後の利益
コストを計算する複雑さ
マーケティングコスト差し引き前の利益
– 不正注文の予測
(最終的に収益と利益の何パーセントが失われるかを見積もる)
– 不正注文とみなされて自動キャンセルされた場合、それを判断できるか(自動キャンセルフラグの有無)
マーケティングコストを差し引いた後の利益
– 特定の注文に帰属するマーケティング費用を考慮する必要がある 素朴な帰属モデル(naive attribution model)を持っているだろうか?
例えば、価格によって重み付けされた品目に帰属するマーケティングコスト マーケティングコストは、部門ごと、商品カテゴリーごと、または最も洗練された組織では、ユーザー広告のクリックに基づく個々の商品ごとに帰属させることもできる つまり、注文を特定の広告および広告コストにリンクするモデルを統合する必要がある
そのデータはETLで作りだすものか、広告プラットフォームから取り出すものか これが派生データの典型例(他のデータから計算されたデータのこと)
派生データの厄介さ
派生データをETLで作っている場合、ETLを変更した場合の作業コストが大きい
(ロジックの理解、変更前の知見、変更後の一貫性/正確性の検証)
派生データがDWHにない場合、アナリストに頼ることになる
だけど…getting analysts to update their reporting queries consistently is well-nigh impossible(アナリストに一貫してレポーティングクエリを更新してもらうことは、ほとんど不可能です) だそうです
一つの興味深い代替案
ビジネスロジックをメトリクスレイアーにpushすること
メトリクス・レイヤーはビジネス・ロジックをエンコードし、アナリストやダッシュボード・ユーザーが定義されたメトリクスのライブラリから複雑な分析を構築できるようにする
メトリクス・レイヤーは、メトリクスからクエリーを生成し、データベースに送信
