
勉強会用の発表資料です
今回の範囲はChapter 8. Queries, Modeling, and Transformationの「Transformations」あたりです
- Transformations
- Batch Transformation
- Broadcast join
- Shuffle hash join
- ETL, ELT, and data pipeline
- Batch Transformation
目次
Transformations冒頭
「なぜTransformationが必要か」
データをモデリングし、クエリーを実行し、結果を得ることができるのであれば、なぜトランスフォーメーションが必要なのか?
例
特定のデータセットの結果を見たいときに
一日に何十回、何百回と同じクエリを実行
20個のデータセットのパース、クレンジング、結合、ユニオニング、集計が含まれていて
クエリの実行に30分かかる
–> コストがかかりすぎる
答え
変換はデータを操作し、拡張し、将来の利用に備えてデータを保存し、その価値をスケーラブルで信頼性があり、コスト効果的な方法で増大させます
クエリの結果を保存することで再利用できる
追加の変換やクエリで使用できる
もう一つのクエリと変換の違い
(transformationを利用しないと)テーブル式、スクリプト、DAGを組み合わせることで単一のクエリで複雑なデータフローを構築することはできますが、一貫性がなくなり、扱いにくくなる
変換はオーケストレーションに重要に依存しており、複数のデータフローと中間結果の再利用が含まれる複雑なパイプラインを構築します
オーケストレーションとtransformationを組み合わせることで、
データを一時的または永続的に保存する中間トランスフォーメーションなどが利用でき、
複雑な処理(別システムのデータとの結合など)も対応できる
Batch Transformation
Distributed joinsの概要
分散結合(Distributed joins)の手法2つを紹介
- Broadcast join
- Shuffle hash join
Distributed joins(分散結合)とは?
一つのQuery(論理結合)が実行されて、結果を取得するために複数のコンピュータ(ノード)が処理を行う
結合に参加するテーブルのサイズによって処理方法が変わる
MapReduce, BigQuery、Snowflake、Sparkなどで使われている手法
「MapReduce, BigQuery、Snowflake、Sparkなどで使われている手法」の説明でパッとしなかったので
「分散ベータベース、Distributed SQL Engine、分散SQL」などのワードで色々調べてみました
そもそもDistributed SQLとは
分散データベースは、ネットワーク上に複数存在するデータベースを、あたかも一つのデータベースであるように利用する仕組み
例えばAWS のAthenaは、Prestoと呼ばれる distributed SQL engine を内部で使用している
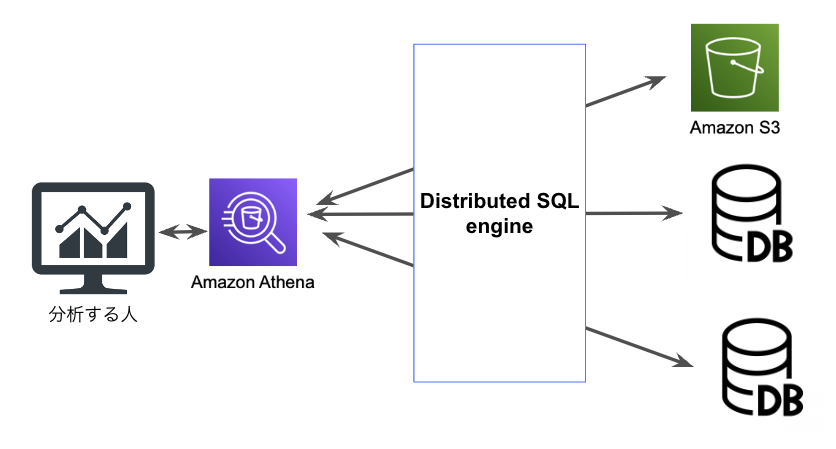
queryを投げて、複数のデータソースからデータ抽出が可能
(スキーマ情報の設定など色々面倒くさい処理は必要ですが..)
RDBでの結合
比較対照としてRDBでは下記のような結合アルゴリズムがある
| 結合アルゴリズム | 備考 |
| Nested Loops | 今回のBroadcast joinの内容に近い(たぶん..) |
| Hash | 今回のShuffle hash joinの内容に近い(たぶん..) |
| Sort Merge | Nested Loopsが非効率な場合、Hashと並んでもう一つの選択肢になる方法 |
Broadcast join
ブロードキャスト結合は、一方の大きなテーブルをクラスタ内の複数のノードに分散し、もう一方の小さなテーブルを各ノードにコピー(複製)します

わからんので自分なりに噛み砕いてみました(下へ続く)
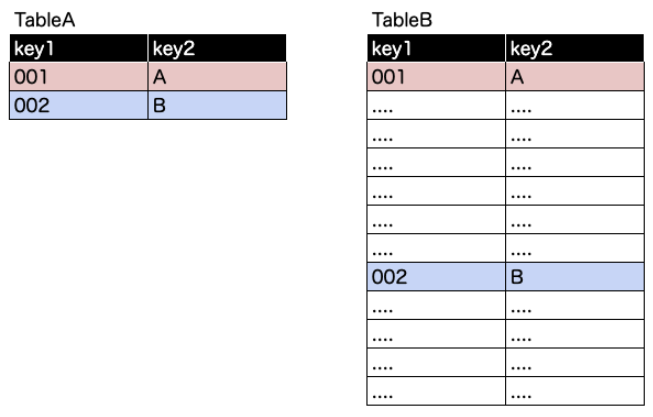
Step0: join対象のテーブルが下記とする
TableAの方がデータが小さいことが特徴
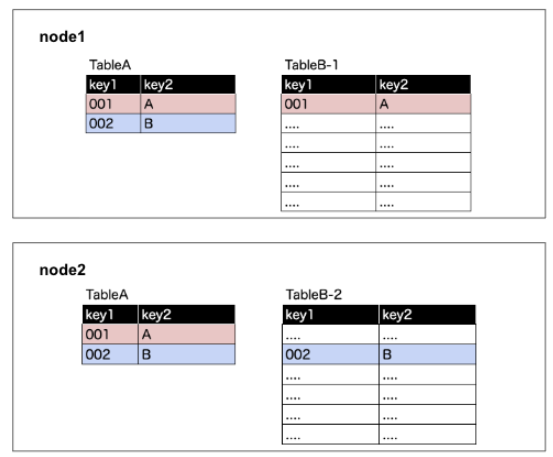
Step 1.「 TableAを丸ごと複製したもの」と「TableBを分割したもの」を各ノードに振り分ける
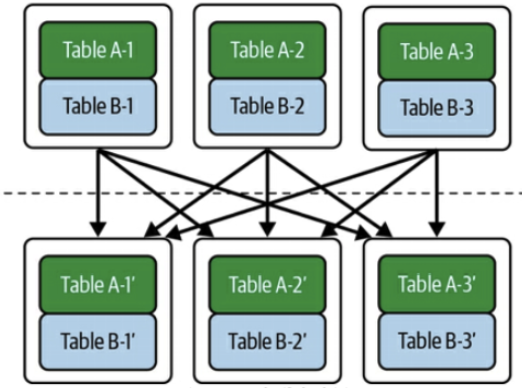
その後、各ノードで結合処理をして、それぞれノードが出した結果を合わせる
特徴
シャッフルハッシュ結合よりもはるかに計算量が少ない
実際には、テーブルAは元は大きなテーブルであっても、クエリエンジンがフィルタリング処理を行なってくれて、ブロードキャストしてくれていることが多い
joinの前の段階でデータ量を少なくしておくことでパフォーマンスが上がる
Shuffle hash join
同じキーをもつデータを同じ場所に集めて処理することで、計算を効率的に行う
こちらもわからないのでもう少し噛み砕いてみました
Step 0. 1つのノードに収まりきれないサイズのテーブルが2つ
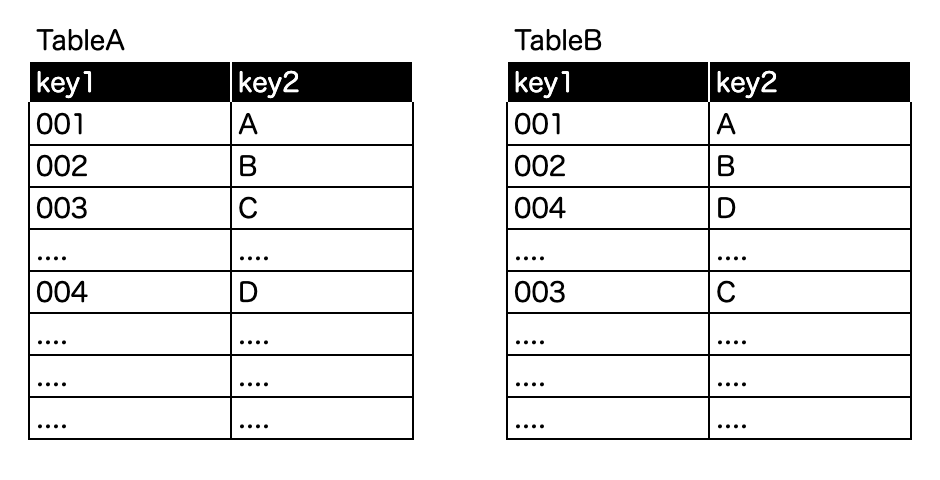
Step1. レコードを均等にノードに割り当て
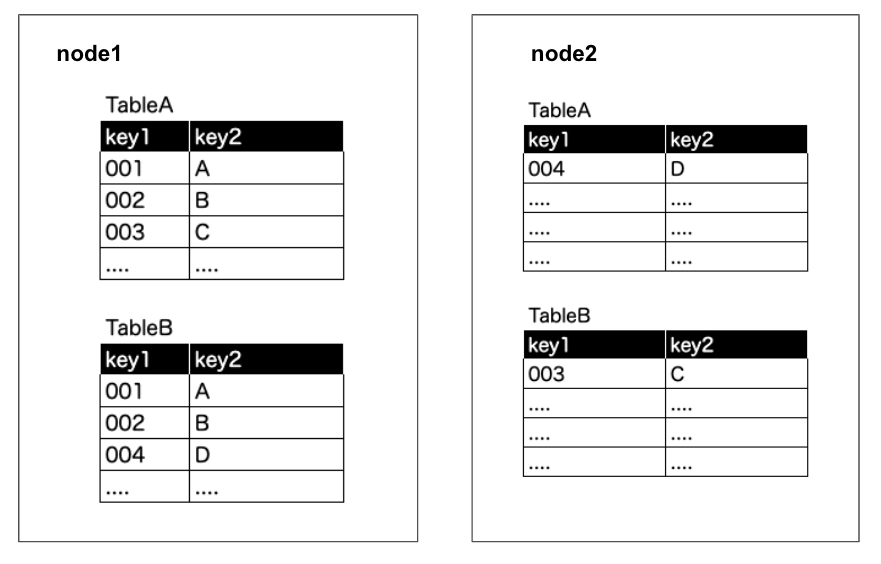
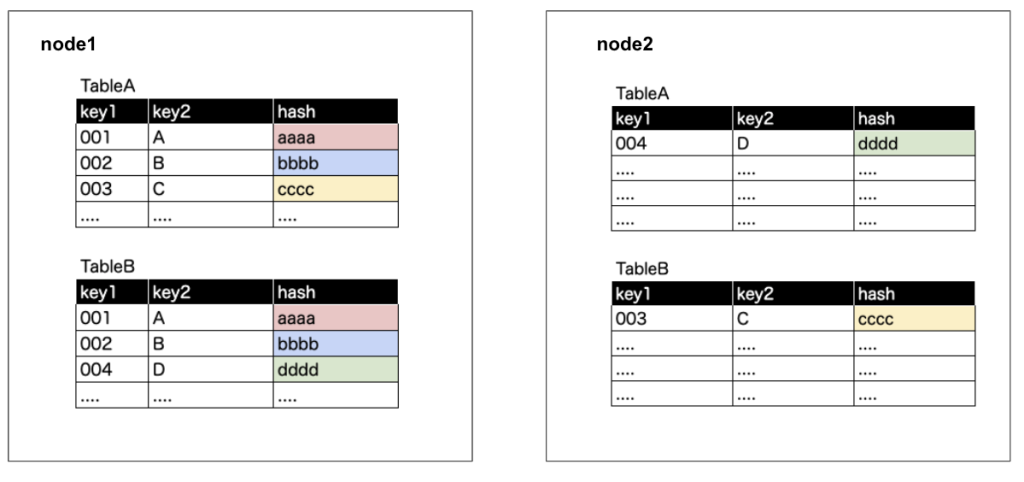
Step2. 結合keyのhash値を出す
hash計算のイメージ
hash(key1 + key2)この結果の値がe9d71f5ee7c92d6dc9e92ffdad17b8bdのような値
以降の例ではaaaa, bbbbの値がhashした結果とする
Step 3 再配置
各ノードにhash値ごとにレコードを配置し、各ノードで結合処理を行う
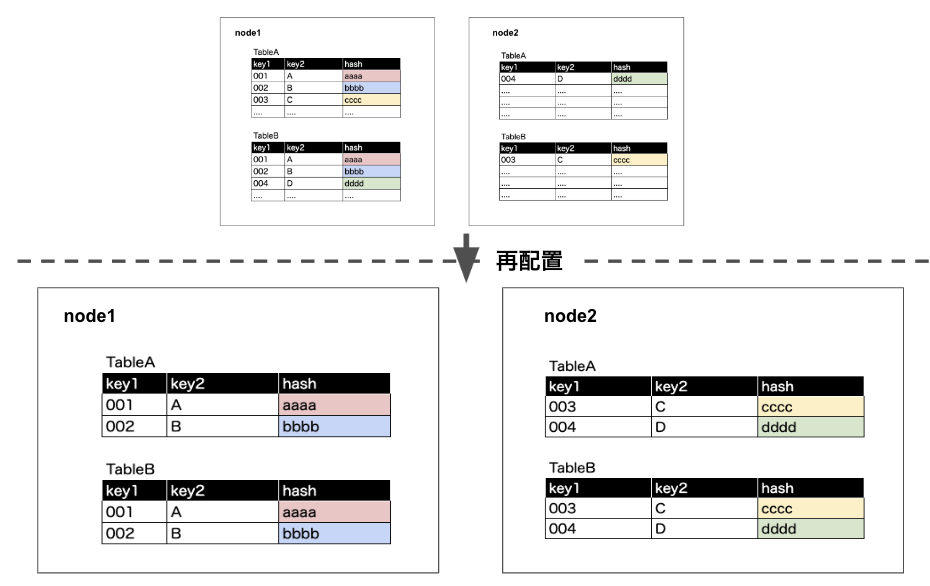
その後、各ノードで結合処理をして、それぞれノードが出した結果を合わせる
Distributed joinsのまとめ
| 種類 | 条件 | 消費リソース |
| Broadcast join | 片方のテーブルが1つのノードに収まるサイズの場合 | 少ない |
| Shuffle hash join | どちらのテーブルも1つのノードに収まるほど小さくない場合 | 高い |
ETL, ELT, and data pipeline
(最近のETL事情が書かれている)
元々普及していたのはバッチ ETL
データマートやキンボール・スタースキーマのようなターゲッ トスキーマ用にデータを準備しながら、データを取り込み、変換し、クリーニングする
下記の問題をクリアするためにこの方法が良しとされていた
– 抽出フェーズがボトルネックになりがち
– 変換は専用システムで処理
– ターゲットシステムは、ストレージと CPU 容量の両方において、非常にリソースに制約があった
今一般的になっているのはELT
ソースシステムから極力変換を行わず生データとしてDWHに取り込む
DWHで変換処理を行う
さらに少し別バージョンのELT
全く変換せずにデータをDWHなどに取り込む
変換が必要になるかどうかは未定
変換が必要になったらDWHで変換処理を加える
これはdata swampの原因となりうる(Inmonも否定的)
data lakehouseの環境では、ETLとELTの境界線がやや曖昧になる
- オブジェクトストレージをベースレイヤーとするDWH
- データフェデレーション、仮想化、ライブテーブルの出現によってさらに曖昧になる(この内容は次回以降の内容で再び登場)
ETLやELTという用語
今後は、組織全体の変換パターンを表すのではなく、個々の変換パイプライン内でのみ適用される用語にした方が良さそう
組織がETL, ELTを標準化する必要はない
exacerbate: 悪化させる
repetitions: 繰り返し
subsequent: 次の、後の、それに続く、その後の、後続の
so subsequent queries are simplified
そのため、以降のクエリは簡略化される
persists: 固執する,頑張り通す,し続ける
ephemerally: 一時的に、短命で、はかなく
unwieldy: 扱いにくい、手に負えない
inconsistent: 一貫性のない
discrete: 別々の・分離した
intermediate: 中間の
span: またがる、(橋が川に)かかる
resource intensive: リソースを大量に消費する
whatsoever: どんなものであれ、何であれ、いかなる
recipe: レシピ
ambiguity: 曖昧さ

