
目次
Whom You’ll Work With
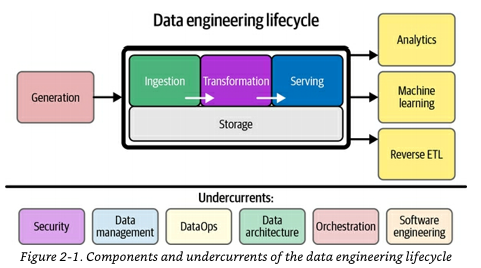
クエリ、変換、モデリングは、データエンジニアリングライフサイクルの上下のすべてのステークホルダーに影響を与える
データエンジニアは、クエリやデータ変換を行うシステムの設計、構築、整合性の維持を行う
このシステム内にデータモデルを実装する段階がもっとも「フルコンタクト」
機能するシステムと信頼できるデータの両面で、可能な限りの価値を付加することに重点を置くことになる
Upstream Stakeholders
上流のステークホルダーは2種類に分けることができる
– ビジネス定義をコントロールする者
– データを生成するシステムをコントロールする者
ビジネス定義やロジックについて上流のステークホルダーとやり取りする際は、
(データエンジニアが)データソースについて、その内容、使用方法、ビジネスロジックや定義について知っておく必要がある
– ソースシステムを担当するエンジニア
– 補完的な製品やアプリを監督するビジネス利害関係者
データ・モデルの設計に関与する必要がある
– ビジネス・ロジックの変更や新たなプロセスによる更新
– 「クエリを書いて、結果をテーブルやビューに入れる」と「パフォーマンスとビジネス上の価値が両立するように作成する」は別問題
– データを変換する際には、常にビジネスの要件と期待を念頭におくこと!
上流システムの利害関係者は、クエリや変換がそのシステムに最小限の影響しか与えないようにしたいと考えている
「データエンジニア」<– >「上流システムの利害関係者」の双方向のコミュニケーションを確保しておく
– ソースシステムの変更(カラム追加など)は、クエリ、変換に直接影響が出るため
– データのクエリ、変換に影響を与える、スキーマの変更については知っておく必要がある
Downstream Stakeholders
変換は、データが下流のステークホルダーに有用性を提供し始める場所
データアナリスト、データサイエンティスト、MLエンジニア、そして “ビジネス “に提供される
データエンジニアが提供したデータモデル/変換が有用性を持つように協力すること!
有用とは?
– アナリスト、データサイエンティスト、MLエンジニアからすると
– データが最高の品質と完全性を持って、ワークフローやデータ製品に統合できるという確信を持って、データソースにクエリを実行できる状態
– “ビジネス”
変換されたデータが正確で実用的であることを信頼できる状態
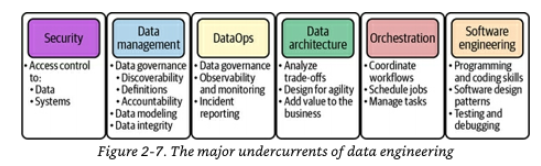
Undercurrents
変換段階は、データが変異し、ビジネスにとって有用なものに姿を変える場所である
多くの可動部分があるため、この段階では特に底流が重要になる
Security
クエリと変換は、バラバラのデータセットを新しいデータセットに結合する
下記を管理すること!
誰がこの新しいデータセットにアクセスできるのか?
もし誰かがデータセットにアクセスできるのであれば、誰がデータセットの列、行、セルレベルにアクセスできるか?
Data Management
データ管理はデータエンジニアリングのライフサイクルの他のすべての段階で不可欠
特にトランスフォーメーションの段階では重要
データモデルと変換にすべての利害関係者を参加させ、彼らの期待を管理することが重要
データの各ビジネス定義に沿った命名規則に全員が同意していることを確認すること!
適切な命名規則は、わかりやすいフィールド名に反映されるべき
データカタログから、そのフィールドの作成意図や、データセットの管理者、その他の情報をより読み取りやすくできる
トランスフォーメーションの段階で重要なのは定義の正確さ
– 利用者の期待しているビジネスロジックに合致しているか
セマンティックレイヤー、メトリクスレイヤー
– 変換内でビジネスロジックを強制する代わりに、これらの定義を変換レイヤーの前の独立した段階として保持する手段がますます一般的になってきている
参考: Transform〜メトリクスレイヤーとは何か? データ分析に必要な「指標」を管理する – Speaker Deck
(変換では)使用しているデータに欠陥がなく、真実のデータを表していることを確認することが重要
– MDM (Master Data Management)が企業のオプションである場合はそれに頼ることを推奨
コンフォームド・ディメンジョンやその他の変換は、データの元の整合性と真実の根拠を保持するために MDM に依存している
MDM: 企業のデータを信頼できる形で管理し、他のビジネス部門がそのデータを容易に利用できるようにするための規律やテクノロジー マスター・データ管理とは | オラクル | Oracle 日本
コンフォームド・ディメンジョン: 異なるデータセットやデータソースで共通して使われるディメンジョン(属性や要素)
MDMを使う選択肢がない場合は、利害関係者と協力して「データが正しく、合意されたロジックに準拠して変換されていること」を確認する
データリネージツールは貴重(特に下記の両者にとって)
– 新しい変換を作成する際に以前の変換ステップを理解する必要があるデータエンジニア
– クエリを実行したりレポートを作成したりする際にデータがどこから来たのかを理解する必要があるアナリスト
規制/コンプライアンスはデータモデルや変換にどのような影響を与えるのか?
– 機密性の高いフィールドがマスク、難読化されているか?
– 削除要求に応じて削除する機能はあるか?
– データ・リネージ・トラッキングにより、削除されたデータから派生したデータを確認したり、変換を再実行して未加工ソースの下流にあるデータを削除したりできますか?
DataOps
クエリとトランスフォーメーションにおいて、DataOpsはデータとシステムという2つの着目する
これらの領域における変化や異常を監視し、アラートを出す必要がある
data reliability engineerと呼ばれる職種もあるほど、data observability(データ可観測性)の分野は注目されている
DataOpsの「Data」
データ品質に関する着目点
– 入力と出力は正しいか
– それをどう判断するか
– このクエリがテーブルに保存される場合、スキーマは正しい
– データの形状や、最小値/最大値、NULLカウントなどの関連統計はどうか
入力データセットと変換後のデータセットに対してデータ品質テストを実行し、データが上流と下流のユーザーの期待に応えていることを確認する必要がある
DataOpsの「Ops」
システムのパフォーマンス、クエリ・キューの長さ、クエリの同時実行数、メモリ使用量、ストレージ使用量、ネットワーク遅延、ディスクI/Oなどのメトリクスを監視
これらのデータを利用してボトルネックやパフォーマンスの悪いクエリを見つけ出す
ここに問題が見つからない場合でも、データベース自体をチューニングする場所の良いアイデアを得ることができる
データ駆動型のアプローチをとり、観測可能性のメトリクスを使用して、クエリかシステム関連の問題かを突き止めましょう
FinOps
オンプレミスのデータウェアハウスの時代
– システムとライセンスは前払いで購入し、追加の利用コスト無し
– 高価な購入品から最大限の効用を引き出すためにパフォーマンスの最適化に重点を置いていた
現在
– 消費ベースで課金される
– コスト管理とコストの最適化に重点を置く必要がある
これがFinOpsの実践
Data Architecture
崩壊することなくデータを処理・変換できる屈強な(robust)システムを構築する
取り込みとストレージの選択は、信頼できるクエリと変換を実行する一般的なアーキテクチャの能力に直接影響します
インジェストとストレージがクエリと変換のパターンに適切であれば、問題はありません。
一方、クエリや変換が上流のシステムとうまく機能しなければ、大変なことになる
間違いの例
– リアルタイム・データ・パイプラインをRDBMSやElasticsearchに接続し、これをデータウェアハウスとして使う
– 大量の集計OLAPクエリに最適化されていないため破綻する
アーキテクチャの選択に内在するトレードオフを理解し、データモデルが取り込みシステムやストレージシステムとどのように連携し、クエリがどのように実行されるかを明確にしてください
Orchestration
最初は単純な時間ベースのスケジュール(cronジョブなど)でうまくいくが、ワークフローが複雑になるにつれて悪夢に変わる
オーケストレーションを使って依存関係ベースのアプローチを行いましょう!
複数のシステムにまたがるパイプラインを組み立てるための接着剤でもある
Software Engineering
transformationの処理を実装する方法は多数ある
– 言語: SQL, Python, JVM
– プラットフォーム: データウェアハウス、分散コンピューティングクラスター
それぞれの言語とプラットフォームには長所と癖があるため、使用するツールのベストプラクティスを知ってきましょう!
例) Python でSparkやDaskのような分散システムで実行する場合
– ネイティブ関数の方がずっとうまくいくかもしれないのにUDFを使ってしまう
– 筆者は低速なUDFを組み込みSQLコマンドに置き換えることで、パフォーマンスが即座に劇的に向上した事例を見てきた
「アナリティクス・エンジニアリングの台頭は、コードとしてのアナリティクスという概念により、ソフトウェアエンジニアリングの実践をエンドユーザーにもたらす」
– dbtのようなアナリティクスエンジニアリング変換ツールは爆発的に普及している
– アナリストやデータサイエンティストはデータエンジニアが直接介入することなく、SQLを使用してデータベース内の変換を記述することができる
– データエンジニアはアナリストやデータサイエンティストが使用するコードリポジトリやCI/CDパイプラインのセットアップを担当する
これまで基礎となるインフラを構築・管理し、データ変換を作成していたデータエンジニアの役割を大きく変えるもの
データチーム全体でより民主化されるにつれて、データチームのワークフローがどのように変化するか興味深い
GUIベースのローコードツールを使用することで、変換ワークフローの有用な視覚化を得ることができる
がしかし
– 内部で何が起こっているのかを理解しておきましょう!
– これらの変換ツールは裏でSQLやその他の言語を生成する
– しかし、ツールがパフォーマンスの高いコードを生成していると盲信するのは間違いだ
データエンジニアは、クエリと変換の段階でソフトウェアエンジニアリングのベストプラクティスに特に注意を払うことをお勧めする
データセットの処理リソースを単純に増やすことは大事、でもクリーンでパフォーマンスの高いコードを書く方法を知ることがもっと大事
Conclusion
変換はデータパイプラインの中心に位置する
なのでトランスフォーメーションの目的を念頭に置きましょう
トランスフォーメーションは、データがビジネスに価値とROIを付加する場
我々の意見は、エキサイティングなトランスフォーメーション・テクノロジーを採用し、ステークホルダーにサービスを提供することは可能
第11章では、ライブ・データ・スタックについて取り上げる
基本的に、ストリーミング・データの取り込みを中心にデータ・スタックを再構成し、トランスフォーメーション・ワークフローをソース・システムのアプリケーション自体に近づける
リアルタイム・データをテクノロジーのためのテクノロジーと考えるエンジニアリング・チームは、ビッグデータ時代の過ちを繰り返すだろう
しかし実際には、私たちが関わる組織の大半は、ストリーミング・データから恩恵を受けるビジネス・ユースケースを持っている。テクノロジーや複雑なシステムを選択する前に、このようなユースケースを特定し、価値に焦点を当てることが鍵となる
第9章のデータエンジニアリングライフサイクルのサービングステージ
組織の目標を実現するためのツールとしてのテクノロジーについて考えてみよう

