
範囲
- データ収集フェーズでカギとなる問い
- データ収集はライフサイクルで最もボトルネックになる箇所
- データ収集で考慮が必要な8項目のQustion
- Batch vs Streaming
- Batch と Streamingの特徴
- バッチ処理よりもストリーミング処理が適しているかを確認する8項目のQuestion
- Push versus pull
- Push model, Pull model
- CDC(change data capture)
- streaming ingestion
Downstreamとは下記のことを表しています
- ingestion system
- Datalake, DWH
- ML, Anarytics など

データ収集フェーズでカギとなる問い
著者の経験ではデータの収集はライフサイクルで最もボトルネックになる箇所
ソースシステムはたいていデータエンジニアの管轄外で、ランダムに応答しなくなったり、質の低いデータを提供したりする可能性がある
データ収集処理が原因不明でストップしたり、その結果データフローが止まったり不整合なデータが流れこむ
信頼性の低いソースシステムや取り込みシステムは、データエンジニアリングのライフサイクル全体に波及します。しかし、ソースシステムに関する大きな疑問に答えていれば、問題はない
- 取り込むデータのユースケースは何か?同じデータセットの複数のバージョンを作成するのではなく、このデータを再利用できますか (疑問)一回取り込めばOKな状態か??
- 安定してデータが生成され、収集できるか?データが必要な時に利用可能な状態か
- 収集後のデータの行き先は?(どこに保存されるか?)
- どのくらいの頻度でデータアクセスが必要か
- どのくらいのサイズのデータが取り込まれるか
- 取り込み後のデータの形式は?storageに保存できて、その後変換できる形式か
- 収集後にdownstreamがすぐに扱えるような良い状態のデータであるか、もしそうであれば悪い状態であるケースは考えられるか(いつまで、何が原因で使えなくなるのか)
- ソースがストリーミングの場合、最終的な保存先に保存する前に何かしらの変換が必要か
- ストリーム内でデータを変換するインフライト変換が適切でしょうか
Batch vs Streaming
私たちが扱うほぼすべてのデータは、本質的にストリーミング
ソースで継続的に生成・更新され、バッチ取り込みは、単にこのストリームを大きな塊で処理するための便利な方法
Streaming ingestion
リアルタイム性が特徴
データが生成されるとリアルタイム、またはニアリアルタイムでdownstreamで利用可能な状態になる
リアルタイムと認定されるために必要なレイテンシは、ドメインや要件によって異なる
Batch ingestion
あらかじめ決められた時間間隔か、あらかじめ設定されたサイズのしきい値にデータが達したときに行われる
一方通行のドア
いったんデータがバッチに分割されると、downstreamのコンシューマーのレイテンシーは本質的に制約される
(例)次のバッチ取り込みを待たないとデータが取り込まれない
特にアナリティクスやMLで使用するデータを取り込む方法として、今でも非常によく使われている
多くのシステムでstorageとcomputeが分離され、イベントストリーミングや処理プラットフォームが遍在するようになったことで、データストリームの連続処理がより身近になり、ますます普及している
その選択は、ユースケースとデータの適時性に対する期待に大きく依存する
バッチ処理よりもストリーミング処理が適しているかの問い
- リアルタイムで取り込んだ場合、downstreamのストレージシステムはデータフローの速度に対応できるのか
- ミリ秒単位のリアルタイムのデータ取り込みが必要なのか?それともマイクロバッチアプローチが有効で、例えば1分ごとにデータを蓄積して取り込むのでしょうか?
- ストリーミング・インジェストのユースケースは?ストリーミングを導入することで、具体的にどのようなメリットがあるのか? リアルタイムでデータを取得した場合、そのデータに対してどのようなアクションを取れば、バッチより改善されるのか?
- 私のストリーミング・ファースト・アプローチは、時間、コスト、メンテナンス、ダウンタイム、機会費用の面で、単にバッチ処理を行うよりもコストがかかるのでしょうか?
- インフラが故障した場合、私のストリーミング・パイプラインとシステムは信頼でき、冗長性がありますか?
- ユースケースに最も適したツールは何か?マネージド・サービス(Amazon Kinesis、Google Cloud Pub/Sub、Google Cloud Dataflow)を使うべきか、それともKafka、Flink、Spark、Pulsarなどのインスタンスを自分で立ち上げるべきか?後者の場合、誰が管理するのか?コストとトレードオフは?
- MLモデルを導入する場合、オンライン予測や、場合によっては継続的なトレーニングにはどのような利点があるのでしょうか?
- 本番インスタンスからデータを取得していますか?もしそうなら、私のインジェスト・プロセスがこのソース・システムに与える影響は?
ストリーミングファーストは良いアイデアのように思えるかもしれないが、必ずしも単純ではない
–>追加コストや複雑さが生まれるから
(筆者の考えでは)一般的なユースケースでは、モデルのトレーニングや週次レポートなどでは、バッチが優れたアプローチだと考えられています
ただし、真のリアルタイムストリーミングを使用する場合は、バッチの使用に対するトレードオフを正当化するビジネスユースケースを特定する必要があります
Push versus pull
push modelはソースシステムがどこかにデータを書き出す
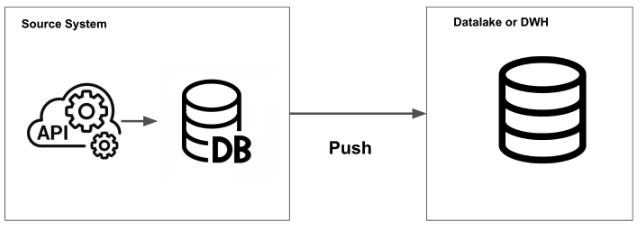
pull modelはソースシステムからデータを抽出する
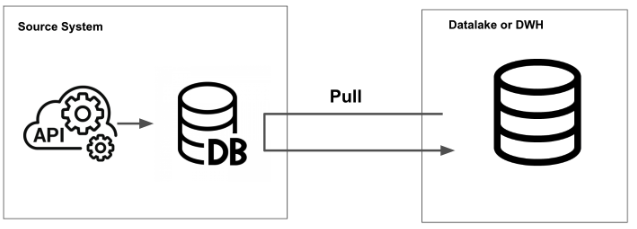
このpush modelとpull modelの境界は曖昧
例えばバッチ行われるETLの場合
Eの部分はソースシステムに対してスケジュール実行でデータ抽出処理をするのでpull ingestion
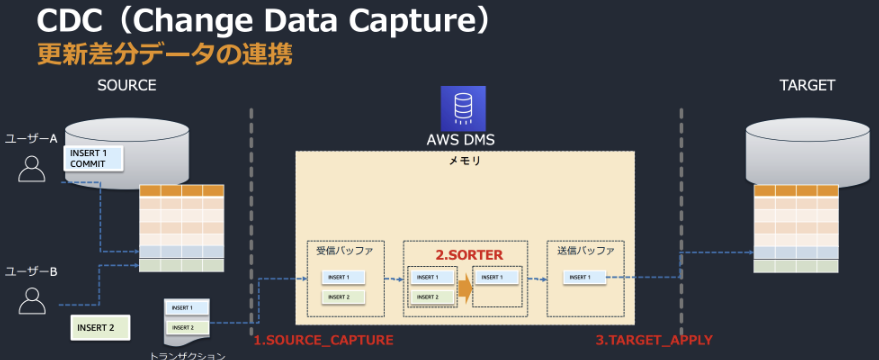
CDC(change data capture)
一般的な方法は、DBの行が変更されるとメッセージキューが発行される、ingest systemがそれをピックアップする
もう一つの方法は、DBは全ての操作に対してlogに追記していくので、ソースシステムはそのlogを読み取る
バッチCDCのバージョンによってはpull modelを使用するものがある、timestamp ベースのCDCはingestion systemがDBに問い合わせ、前回の更新以降に変更された行をpullする
参考: AWS DMS(Database Migration Service) の資料
stream ingestion(ソースDBをバイパス)
ソースDBをバイパスしエンドポイントに直接pushされる
センサーデータを発信するIoTデバイスで有効な方法
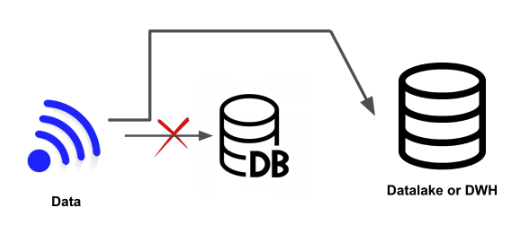
現在の状態を維持するためにDBを利用するのではなく、単に記録された各値をイベントとして扱う
- 人気が出てきている理由
- リアルタイム処理がシンプル
- アプリ開発者(ソースシステム側)がメッセージを調整できる
- データエンジニアへの負荷を軽減
