やること
- RDSからsnapshotの作成を実施
- S3 exportを実行し、snapshotをS3バケットに出力
- Glue Crawlerを実行してS3のsnapshotデータのDataCatalogを作成する
- Athenaからデータを参照出来るか確認する
検証実施
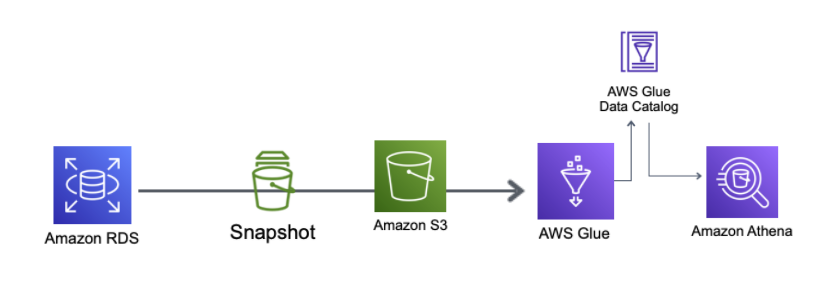
RDSからsnapshotの作成を実施
snapshot作成、S3 exportで設定が必要なKMSの作成、そしてS3 exportの順で行います
RDSの管理画面からスナップショットの取得を実施すると、一覧に表示されます
KMSを作成
その後、S3でのエクスポートを実施します
ここでは下記の対応を行いました
- snapshot用のロールを作成
- S3アクセス用のポリシーを付与
- 先ほどKMSを設定
S3 export開始
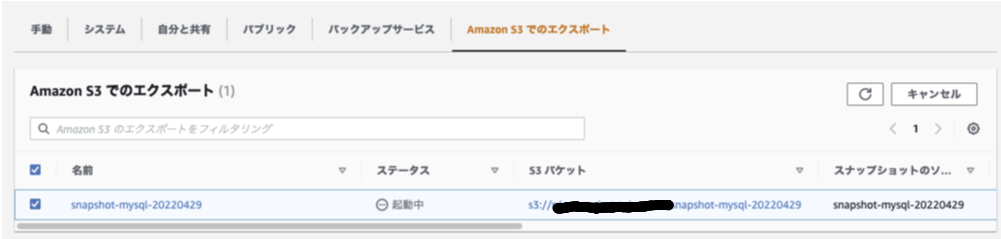
エクスポートが完了したので、S3に保存されているか確認します
無事に出力されているようです
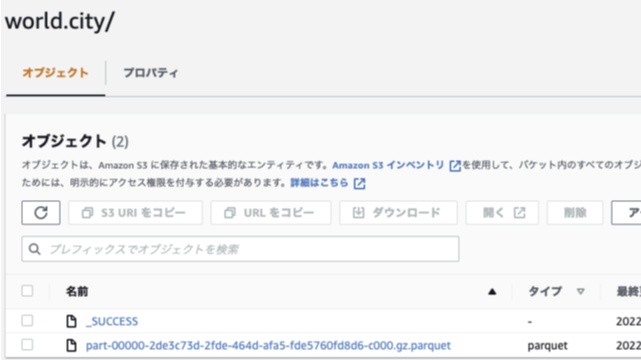
全てのテーブルがフォルダごとに区切られて、parquetファイルで保存されている状態でした
下記はDB名:world , Talbe名:cityのデータが出力されているオブジェクトパスです
Glue Crawlerの作成
Crawler作成後、Crawlerを実行しましたがテーブルが追加されていませんでした
これはGlue Crawler実行用のロールにKMSの設定がされていないのが原因でした
この権限がないとTableが追加されないようです
Before running the crawler, goto customer managed keys and add a key user as glue services role created while configuration of crawler named as AWSGlueServiceRole-test-demo. Note that without this step crawler won’t add tables in Data Catalog.
参考: https://medium.com/gargee-bhatnagar/aws-glue-and-aws-athena-how-to-export-database-snapshots-manually-to-s3-and-export-s3-content-in-1813568b1a3c
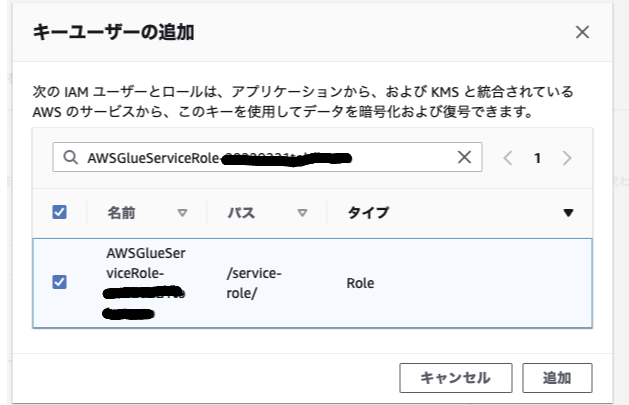
KMSのキーユーザーを追加
Glue Crawlerの実行を可能にするため、KMSのキーユーザを追加します
Crawler再実行
再度crawlerの参照先をsnapshotが出力されたbucketに設定して、crawlerを再作成しました
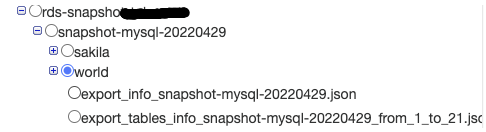
Crawler実行完了後、DataCatalogを確認すると無事にテーブルが作成されていました

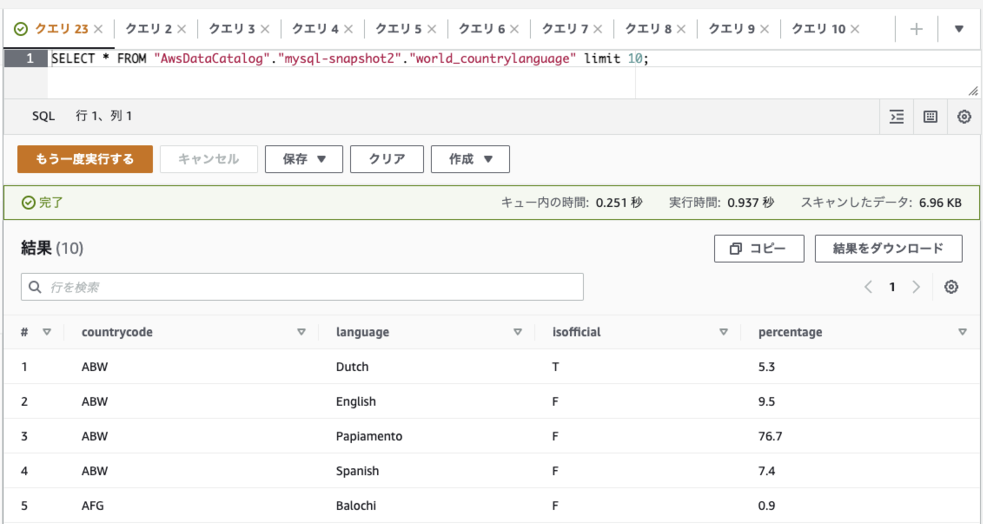
もちろんAthenaからもデータの参照が可能です
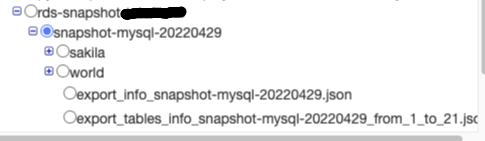
ちなみにcrawlerの参照元をsnapshotのrootのフォルダに設定するとDB名+テーブル名のテーブルが出来上がりました
複数テーブル、複数DBのDataCatalogを作成する場合はこのように上位階層のフォルダを指定すると一度でDataCatalogが作成出来るので便利ですね

最後に
- S3 exportで出力されたデータはparquet形式で、DB名/テーブル名ごとでフォルダが別れて出力されている(Glue Crawlerで読み込ませやすい形式になっている)
- KMSの設定が必要
- Glue Crawlerを実行するRoleにKMSのキーユーザ設定が必要
- Glue Crawlerで読み込むディレクトリを上位階層に設定すれば複数テーブルを一度に作成可能(
xxxxx/table名/データファイルの構成になっていることが前提)
