目次
やること
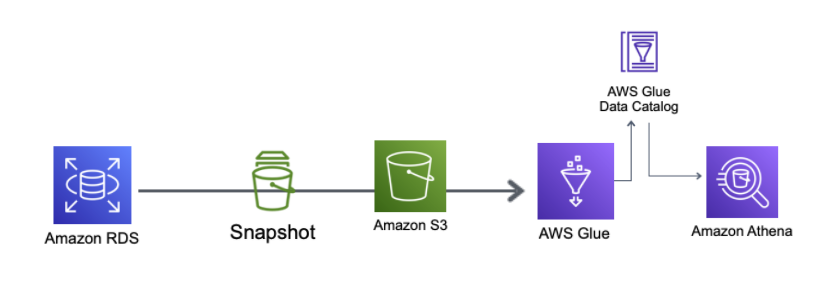
- DBのデータをGlue Jobを利用しparquet形式でS3バケットに出力する
- Glue ConnectionでRDSに接続し、Crawlerを利用してDataCatalogの生成
- Glue Connectionを利用して、Glue JobからRDSへの接続
- DBへの負荷を軽減する目的で、データを絞り込み条件で件数を抑えて抽出できるかを調査
- (補足)Glue Crawler実行時にどんなSQLが発行されているかを調査
Glue Connectionの作成
RDS fro MySQLを構築、ダミーDB作成&データ登録は事前に行っています(色々ハマった箇所もありましたが、、)
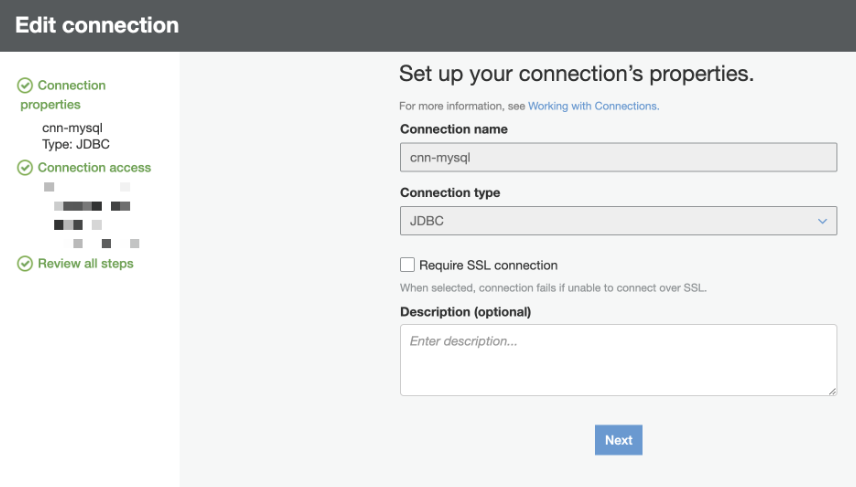
Glue Connection設定
今回はConnection TypeをJDBCで登録します
DB の接続情報とDBが配置されているVPCの情報を入力
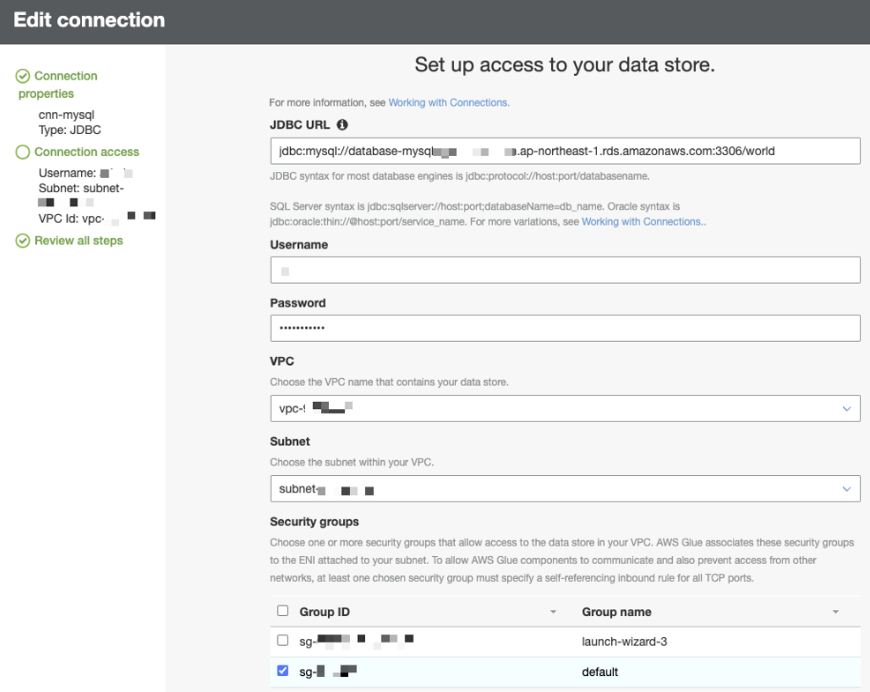
設定が完了したらTest Connectionで正しく接続できるか確認します
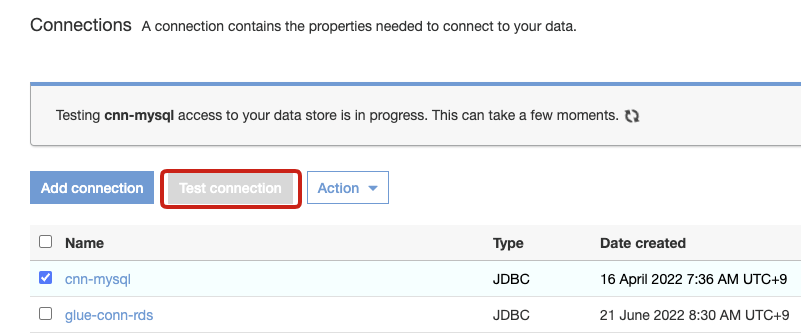
私の場合ここで接続テストが失敗し、下記の2点の対応をしました
- TCP許可設定
- VPCエンドポイント設定
参考サイト- https://qiita.com/hayao_k/items/d212125c850616a4ccb
- https://yohei-a.hatenablog.jp/entry/20200107/1578360057
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/glue-s3-endpoint-validation-failed/
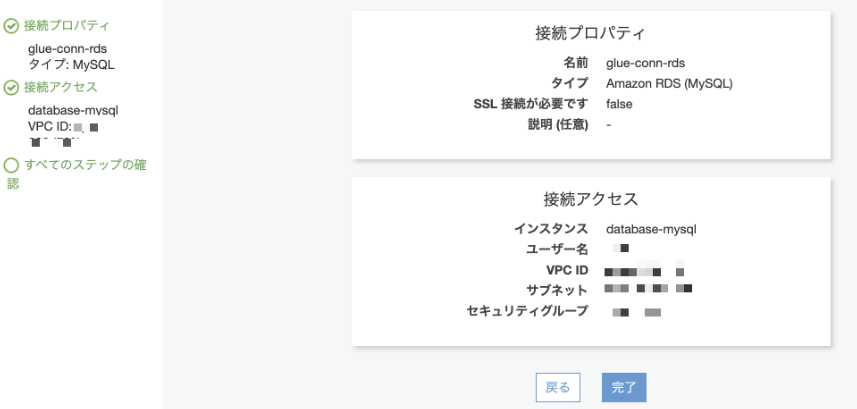
上記のエラーを対応して接続テストがOKになりました
ちなみにタイプでAmazon RDSを選択した場合は、すでに立ち上げている同一アカウント内のRDSの設定(VPC, サブネット、セキュリティグループ)が反映されるようです
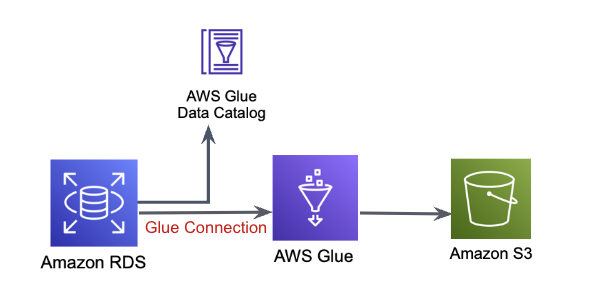
Glue Connectionを使用してDataCatalog作成
Crawler作成
接続の項目にGlue Connectionで作成したConnectionを選択します
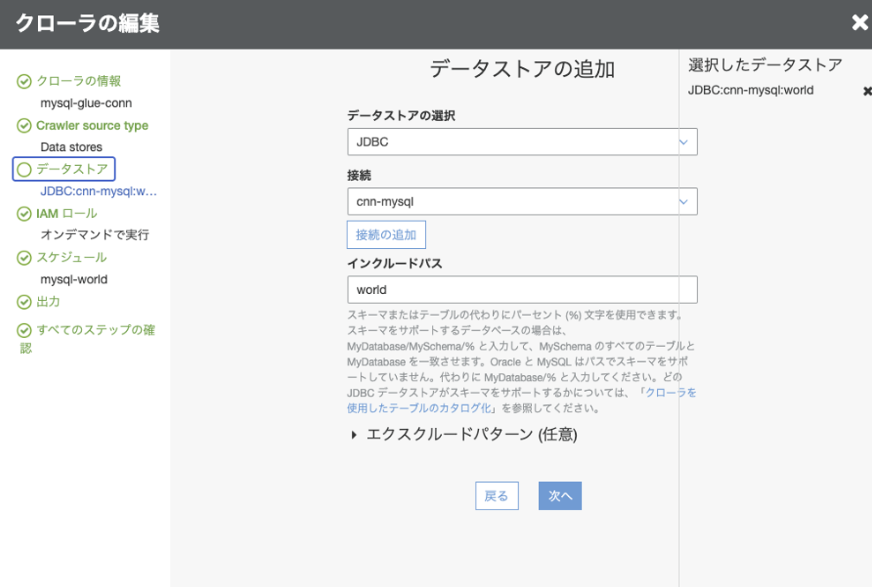
ちなみにGlue Connectionで接続したからと言って、Athenaから直接データを抽出することは不可でした。(Athenaから参照できない状態でした)
Glue Job作成
続いてGlue Connectionを使用し、データをparquetに変換してS3に出力します
今回は手っ取り早くGlue Stadioで自動でコードを生成しました
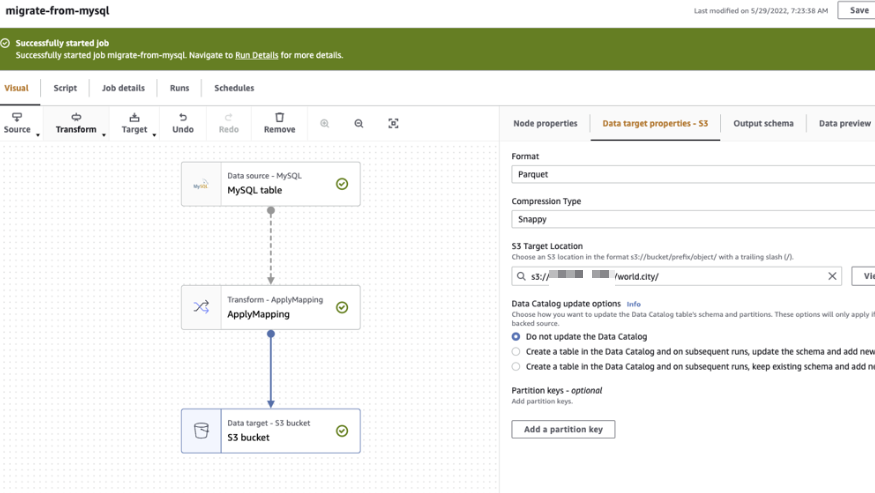
Glue jobを実行後、問題無くS3にparquetが出力されることを確認できました
生成されたparquetを読み込むためのCrawlerを作成します
出力先のデータベース名をmysql-world-collectedに設定

Crawlerを実行するとTableが作成され、Athenaからデータの参照が可能になりました
※この時に「Glue Jobを何度実行してもS3のデータが更新されない」問題にハマったので補足として後日他の記事で残しておきます
後日投稿予定: [RDSのデータを更新後、Glue jobを再実行してもS3のデータが更新されない]
DBへの負荷を軽減する目的で、データを絞り込み条件で件数を抑えて抽出できるかを調査
無事にGlue Connectionを使用して、RDSから抽出したデータをparquet形式でS3に出力することができました
ここからはGlue Connectionの接続先のDBの負荷を考慮するために調査した内容です
RDSのクエリをログに出力するための設定は下記のサイトを参考にしました
Amazon RDS MySQL DB インスタンスのログを有効にしてモニタリングする方法を教えてください。
Glue Jobが実行したクエリの負荷を調査
先ほど実装したGlue Jobを実行した際に発行されるSQL(RDSからのデータ抽出部分のみ)は以下のSQLが実行されていました
SELECT * FROM (select * from city WHERE ((ID <= '4079'))) as cityID=4079は`city`テーブルの最後のレコードです(つまり全レコード取得している)
このクエリの実行計画を確認してみます

この結果の読み方自体よくわからなかったので調べました
https://qiita.com/tsurumiii/items/0b70f1a1ee0499be2002 を読むところ、フルインデックススキャンになっているため、負荷が多くかかる状態だそうです(データが多い場合は注意が必要)
となるとGlue Job実行時のDBへの負荷を軽減するためにも、データ量を絞り込んで抽出するのが理想的です
Glue Job のscript内でFilterで絞り込んでDBからデータ抽出できるか
DBへの負荷を抑える目的で、Glue Jobではデータ量を絞り込んで抽出可能であるかを検証しました
glueContext.create_dynamic_frame.from_options(ではなく glueContext.readを使うと条件付きで抽出できるようです
参考サイト: AWS glueContext read doesn’t allow a sql query
下記のようにurl, user, passwordなどDB接続情報を設定することで任意のSELECT文を実行できました(ちょっとめんどくさいですね)
val t = glueContext.read.format("jdbc").option("url","jdbc:mysql://serverIP:port/database").option("user","username").option("password","password").option("dbtable","(select * from table1 where 1=1) as t1").option("driver","com.mysql.jdbc.Driver").load()この記述を今回利用しているDBのデータ抽出用に変更したものをGlue Jobに実装し、実行すると問題無く意図したSELECT文のクエリが実行されていることがわかりました(DynamicFrameにも絞り込まれたデータが入っていた)
補足:Crawler実行時にどんなSQLを発行しているか
Crawler実行時にDBに投げるSQLを調査し、どれくらい負荷が掛かっているのかを調査してみましたが、、
ログが出力されるmysql.general_logテーブルのevent_timeを絞り込んでデータの抽出を試したところ、データの件数が10万件以上だったので調査を断念しました
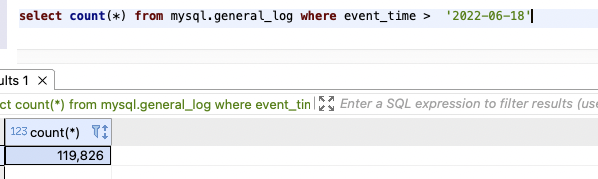
そのためCrawler実行時にDBに掛かる負荷は不明
まとめ
メリット
- Glue ConnectionでDataCatalogを手軽に作れる(Tableメタデータの管理がDataCatalog一箇所でできる)
- RDSから絞り込み無しで抽出したい場合はGlue Connection経由のDataCatalogからデータを抽出できる
- PySparkのおかげで、csvに変換する中間の処理無しでparquetに変換できる
デメリット
- (Glue Script内で)RDSから絞り込み条件をつけてデータ抽出する場合は、Glue Job内でJDBCの接続設定、SQLの準備が必要で、「DataCatalogを使用しつつ、条件オプションを一部つける」などの抜け道はないみたい
- JDBCの接続設定が一から必要であるのであれば、別にGlue にこだわる必要がなさそう